发现有道翻译突然变得像树懒一样慢,别干等着,直接按这三步排查:
-
断网切换测试:把手机或电脑的 Wi-Fi 关掉切蜂窝网络,如果瞬间变快,说明是你当前宽带的 DNS 节点被运营商劫持了,需手动修改 DNS(如改为
223.5.5.5)。 -
下载“离线翻译包”:在客户端设置里,提前把“中英离线包”和“OCR离线识别包”下好,断网也能秒出结果,彻底摆脱服务器排队延迟。
-
清理深层垃圾:PC 端别只在软件里点清理,进入系统
AppData隐藏文件夹,把积压的数十个G的文档缓存删掉,软件响应速度直接翻倍。

作为一个常年和跨国业务打交道、经手过成百上千份多语种资料的打工人,我的电脑和手机里一直常驻着几款翻译工具。有道翻译凭借其对中文语境的深度优化,一直是我们团队的主力工具之一。
但是,这半年来我听到身边不止一个同行在群里吐槽:“有道翻译最近是怎么了?复制一段话进去,那个小圈圈能转上半分钟才出结果!”更有甚者,上传一个十几兆的 PDF,进度条直接卡死在 99% 不动了。
如果你也正在经历这种“翻译一分钟,转圈五十分钟”的折磨,千万别觉得是自己电脑配置不行。其实,翻译软件变慢,90% 的原因都出在本地缓存堆积、CDN 节点调度失败以及未合理利用离线算力上。今天,我就把我们团队在线下实战中总结出来的这套“有道翻译深层提速防坑指南”全盘托出。不讲虚的,直接跟着操作。
一、 核心痛点诊断:为什么你的有道翻译突然变慢了?
在动手修车之前,我们要先搞清楚是发动机坏了,还是油路堵了。有道翻译的底层架构是基于 NMT(神经网络机器翻译)的,这意味着你每一次按下翻译键,数据都要在你的设备和网易的服务器之间跑个来回。
导致翻译速度暴跌的“三大暗雷”:
-
DNS 劫持与 CDN 调度黑洞:这是最常见但也最隐蔽的坑。国内部分小宽带运营商(我就不点名了)为了省网间结算费,会把有道翻译的 API 请求强行路由到一些过期的、甚至是跨省的劣质 CDN 节点上。你的网速测出来是千兆,但连有道的服务器却像是在用拨号上网。
-
文档 OCR 解析把内存“吃干抹净”:之前我们帮客户处理签证和财务材料时发现,直接把带复杂表格的截图丢进软件,特别是涉及 有道翻译如何处理银行流水等高密集排版图文的防坑实操 场景,软件的 OCR(光学字符识别)引擎会疯狂占用本地内存,如果缓存没清,直接假死给你看。
-
高并发期被“限流”:平时下午 2 点到 5 点,或者考试季前夕,是有道服务器最拥挤的时候。如果是免费用户,你的翻译请求会被分配到低优先级的队列里慢慢排队。
了解了病因,接下来我们对症下药。
二、 网络层提速:终结延迟,抢占最优节点
如果你输入一句简单的“Hello”都要转圈好几秒,别怀疑,绝对是网络路由出问题了。
1. 手动修改底层 DNS(立竿见影的奇招)
不要用光猫或者路由器默认分配的 DNS。我们需要手动将其指向阿里或腾讯的公共 DNS,强制刷新获取有道翻译最快的服务器 IP。
Windows 端实操步骤:
-
右键点击屏幕右下角的网络图标,选择“网络和 Internet 设置”。
-
找到“更改适配器选项”,右键你的当前网络(Wi-Fi 或以太网),点击“属性”。
-
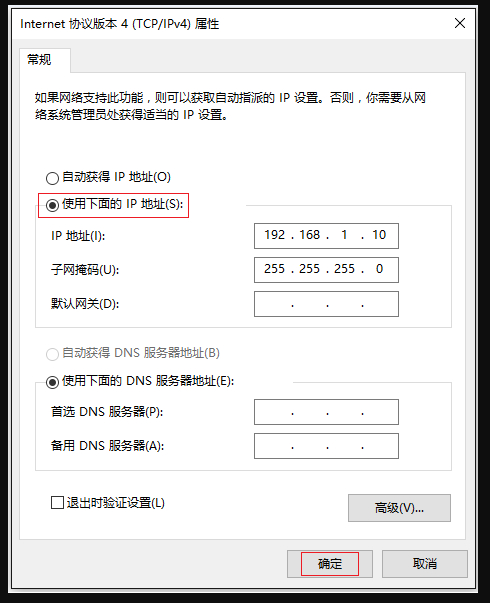
双击“Internet 协议版本 4 (TCP/IPv4)”。
-
勾选“使用下面的 DNS 服务器地址”,将首选 DNS 设为
223.5.5.5(阿里),备用设为114.114.114.114。 -
一路点击确定,然后按下
Win + R键,输入cmd,在黑框里输入ipconfig /flushdns按回车清空旧记录。
2. 移动端秒开技巧:防 Wi-Fi 假死
如果你在用手机版有道翻译(不管是 iOS 还是 Android),遇到一直加载的情况,最暴力的解法是:下拉控制中心,关闭 Wi-Fi,用 5G/4G 蜂窝数据翻译。
蜂窝网络的基站基带通常不会对特定的 API 域名做劫持,99% 的情况下切到流量瞬间就能出结果。
三、 本地端爆改:榨干本地算力与清理“隐形垃圾”
网络修好了,如果遇到大段文字或者长文档还是慢,那就是你电脑本地的锅了。
1. 终极大招:开启并下载“离线数据包”
这是被无数人忽略的宝藏功能。现在的手机和电脑 CPU 算力早就过剩了,完全没必要每次都去云端求爷爷告奶奶。
-
如何操作:打开有道翻译 PC 版或手机版,进入“设置” -> “离线包/离线数据”。
-
核心动作:把“中英基础词库”、“中英神经网路翻译包(NMT)”以及“离线 OCR 识别包”统统下载下来。
-
惊人效果:下载完成后,你可以尝试断开电脑的网络。你会发现,日常的中英互译不仅能用,而且是真正的毫秒级“秒出”!因为所有的翻译运算都在你本地的 CPU 上完成了,直接绕过了糟糕的公网环境。

2. 深层铲除“隐形缓存”(专治客户端越用越卡)
上个月有个刚入行的翻译小助理跑来找我,说她的有道词典 PC 版卡得连打字都一顿一顿的。我点开软件自带的“清除缓存”,显示只有 50MB。但我太了解这些软件的德性了。
只有内行才知道的真实清理路径(以 Windows 为例):
你平时翻译的网页、长截图、PDF 文档碎片,都被它悄悄塞进了系统隐藏文件夹里。
-
打开“我的电脑/此电脑”,在上方地址栏输入:
%AppData%并回车。 -
向上退一级到
Local文件夹。 -
找到名为
Yodao或Youdao的文件夹,点进去寻找Dict相关的目录。 -
里面通常会有一个叫
Cache或Temp的子文件夹。好家伙,我打开小助理的那个文件夹一看,足足堆了 8.5个G 的临时碎文件! -
果断把里面的文件全部 Shift+Delete 永久删除(别怕,不会影响你的生词本和账号数据)。重新打开软件,丝滑如初。
四、 进阶防坑:不同类型文档的“正确喂食姿势”
很多时候速度慢,不是软件的问题,而是你“喂”给它的姿势不对。不同的输入内容,要用不同的翻译通道。
1. 超长文本与法律合同:拒绝“一锅炖”
对于高密度的专业文本,尤其是当你还在纠结 有道翻译是否适合处理严谨的法律合同文本、担心翻译准确度时,绝对不要把几万字一次性复制粘贴到左侧的文本框里硬转!
-
踩坑教训:左侧的快捷翻译框通常为了追求速度,分配的并发算力有限。一次性塞入超过 5000 字,极易触发服务器的“防刷机制”,直接给你断流,导致一直转圈。
-
正确姿势:把文本保存为 Word(.docx)格式,点击顶部的“文档翻译”功能,把文件传上去。文档翻译走的是独立的批处理队列,虽然上传后需要等个几十秒排队,但一旦开始处理,稳定性和排版保留度远超直接粘贴,且极少出现假死。
2. 高清长图与扫描件:先压缩,后上传
图片翻译慢,90% 的时间花在了本地把图片“上传”到服务器,以及服务器“看图识字(OCR)”的过程。
如果你直接用手机原相机拍了一张 10MB 大小的合同扫描件传上去,不慢才怪。
-
老鸟建议:在上传图片翻译前,随手用微信发给文件传输助手(勾选普通发送,不选原图),然后再保存下来,图片通常会被压缩到 1MB 以内。此时再扔进有道翻译,识别速度能提升三倍以上。
五、 全端对比:网页版 vs 客户端 vs 插件,哪个才最快?
我们团队为了追求极致效率,曾经对有道翻译的三个主要终端做过测速对比。如果你对速度有极高要求,请仔细看这张表:
| 使用终端 | 响应速度 | 适用场景与优缺点 | 实战建议 |
| 网页版 (Web) | ⭐️⭐️⭐️ | 随开随用,不占本地内存。但纯靠网速,容易受浏览器缓存拖累。 | 适合偶尔查个词、翻译几句短语。不可用于百兆级别大文件翻译,极易崩溃。 |
| 浏览器插件 | ⭐️⭐️⭐️⭐️ | 划词翻译速度极快,阅读外文网站神器。 | 推荐在 Chrome/Edge 浏览器安装,专门用来对付网页端的外文资料。 |
| PC/Mac 客户端 | ⭐️⭐️⭐️⭐️⭐️ | 地表最强,速度最稳。支持离线包,调用本地算力,无惧断网。 | 重度用户的唯一选择。 |
如果你是靠翻译吃饭或者重度依赖多语种办公的人,别偷懒,老老实实去下个桌面端,把离线包开启,这才是终极的效率保证。
六、 有道翻译提速与排障 SOP 检查清单 (Checklist)
遇到转圈卡顿,不要暴躁,按顺序走一遍这份 Checklist:
-
[ ] 网络急救:手机端立刻切换到 5G 蜂窝网络;电脑端 ping 一下外网,确保不是自身断网。
-
[ ] DNS 校验:检查电脑/路由器的 DNS 是否已修改为
223.5.5.5或其他高可用公共 DNS。 -
[ ] 离线引擎状态:打开客户端设置,确认“离线翻译数据包”和“离线 OCR 包”已下载完毕并处于“启用”状态。
-
[ ] 文本容量检查:确认文本框单次输入的字符没有超过 5000 字的隐形警戒线。
-
[ ] 深层缓存清理:进入系统的
%AppData%目录,彻底清空了旧版本的冗余缓存文件。

七、 常见问题解答 (FAQ)
Q1:网页版有道翻译文档翻译一直停在“正在排队 0%”,怎么解决?
这通常是因为浏览器本身的 Cookie 错误或者被去广告插件(如 AdGuard)拦截了有道的 API 接口。解决办法:使用浏览器的“无痕模式/隐私模式”重新打开有道网页版尝试;或者临时禁用去广告插件刷新页面。
Q2:离线翻译包虽然快,但翻译质量会不会比联网时差很多?
这是一个很现实的问题。联网状态下,有道调用的是云端最新迭代的千亿级参数大模型;而离线包受限于本地硬盘体积,用的是经过剪枝的轻量化 NMT 模型。结论是:对于日常口语、简单邮件和新闻阅读,离线包的质量肉眼看不出区别,且速度秒杀联网;但如果涉及晦涩的学术论文或文学修辞,建议还是连上稳定网络,交由云端处理。
Q3:我买了 VIP,为什么翻译 100 页的 PDF 还是提示错误或解析失败?
VIP 只能让你插队,不能帮你突破物理限制。有道的服务器对单次解析的 PDF 有极其严格的图层检测机制。如果你的 PDF 是那种每一页都带有极其复杂的隐藏矢量水图、或是文件经过加密锁定了文本提取权限,翻译引擎就会一直卡在“解密/解图层”这一步导致超时。正确做法是用 Acrobat 等软件把 PDF “打印为图像 PDF”或者拆分成每份 30 页的小文件,再分批喂给有道。




